My Data Science & Machine Learning Projects
🇮🇹 Corporate Financial Risk Assessment Prototype – Proactive Risk Management
Early identification of corporate financial distress is critical for minimizing credit exposure and supporting informed risk decisions. This machine learning prototype analyzes financial ratios and macroeconomic indicators to predict bankruptcy risk and classify companies by their likelihood of financial failure.
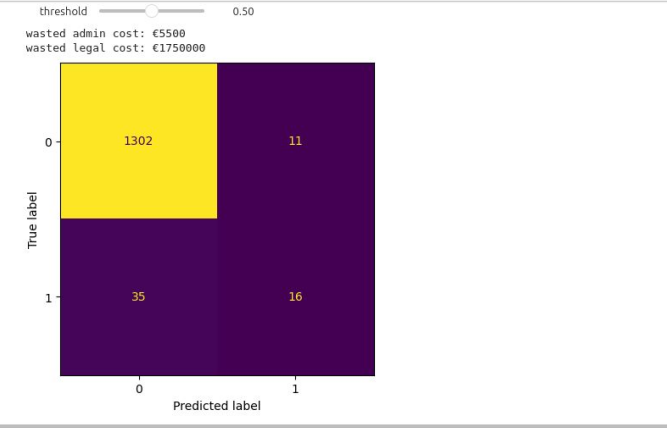
The model achieves 85% predictive accuracy and was intentionally optimized for high recall, reflecting the business reality that the cost of missing a truly high-risk company is significantly greater than the administrative cost of reviewing false positives. This design ensures that the majority of at-risk firms are identified early, enabling proactive intervention and loss mitigation.
Built as an end-to-end analytical prototype, the system can be extended to support automated data ingestion, cloud deployment, model versioning, and continuous performance monitoring in a production risk management environment.
Audience: Financial analysts, credit risk teams, portfolio managers, and corporate strategy stakeholders.
Prediction Accuracy Assessment (Confusion Matrix)
Technologies:
Customer Intelligence & Segmentation Prototype – Targeted Marketing Insights
Broad, one-size-fits-all marketing campaigns often lead to low engagement and wasted spend. This prototype applies customer behavior and purchase data to segment customers into distinct groups, enabling more personalized messaging, targeted offers, and improved campaign performance.
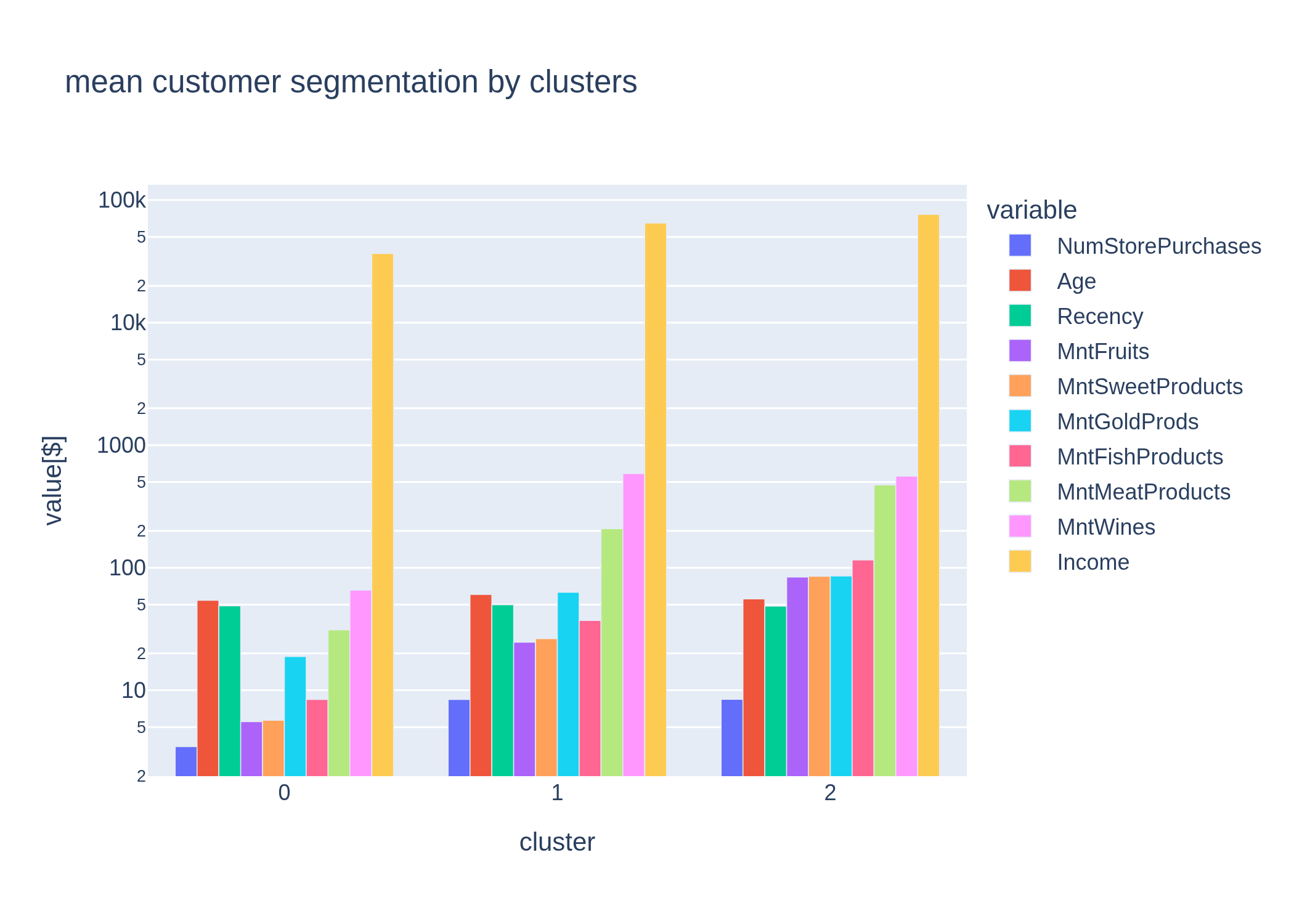
Segment quality was evaluated using Silhouette Score and inertia, which measure how clearly customers fit within their assigned groups and how distinct each group is from the others. Higher scores indicate more meaningful segments that are easier for marketing teams to act on with confidence.
Designed as an extensible analytics prototype, the solution can support automated data updates, dashboard integration, and cloud deployment for ongoing customer intelligence use cases.
Audience: Marketing teams, customer analysts, and business strategy stakeholders.
K-Means Clustering Output: 3 Customer Segments
Technologies:
Market Trend & Volatility Forecasting Prototype – Data-Driven Investment Insights
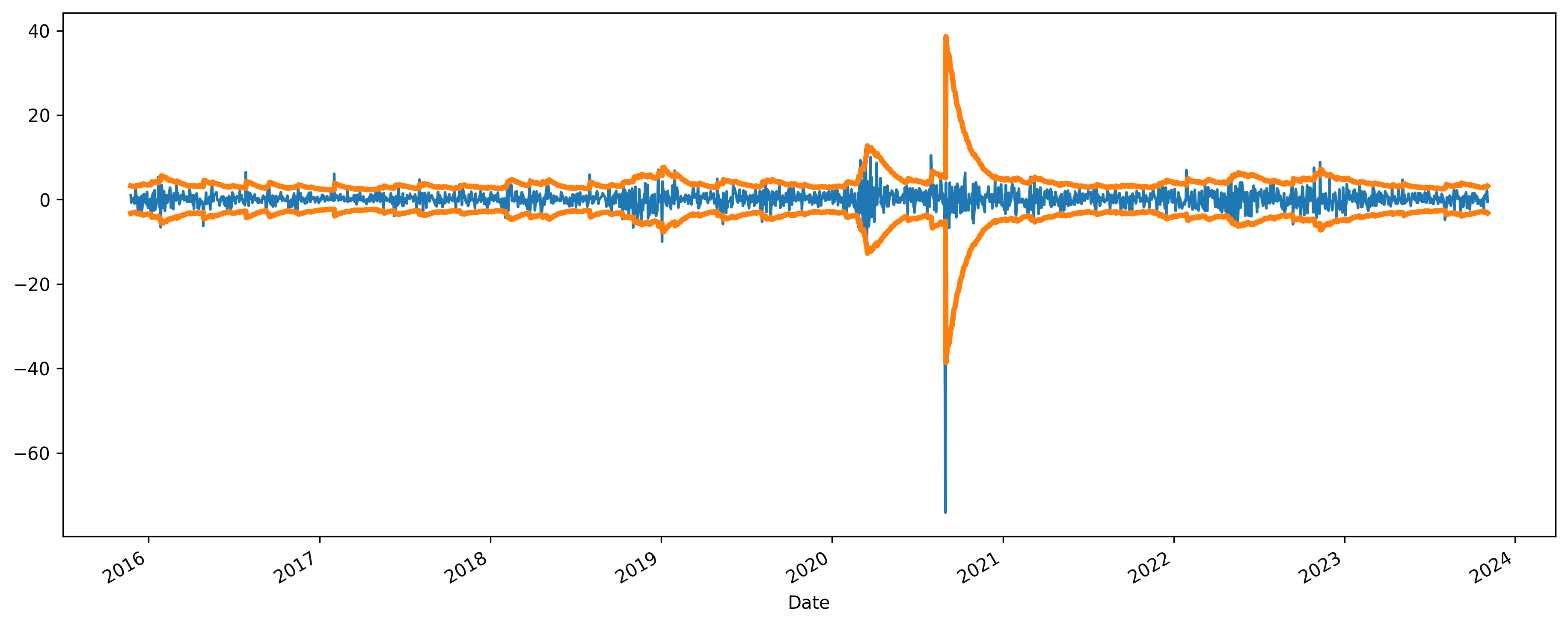
Market volatility directly impacts portfolio risk, capital allocation, and trading decisions. This prototype uses historical and live market data with GARCH-based volatility modeling to estimate future risk levels and identify changing market conditions that may affect investment outcomes.
Model performance was evaluated using AIC and BIC to balance accuracy with model simplicity, reducing the risk of overfitting, and backtesting to verify that predictions would have performed reliably on historical market data. Together, these metrics ensure the model produces stable, decision-ready risk signals rather than short-term noise.
Built as an API-driven system using FastAPI, the prototype can be extended to support real-time data ingestion, cloud deployment, multi-user access, and continuous monitoring in an investment analytics environment.
Audience: Traders, portfolio managers, financial analysts, and investment strategy teams.
Conditional Volatility Analysis of Apple Stock (±2σ Bands)
Technologies:
📞 Data-Driven Customer Retention Prototype – Proactive Churn Management
Customer churn directly impacts revenue growth and lifetime value, while acquiring new customers is significantly more expensive than retaining existing ones. This prototype identifies customers at risk of churn early, enabling targeted retention actions before revenue is lost.
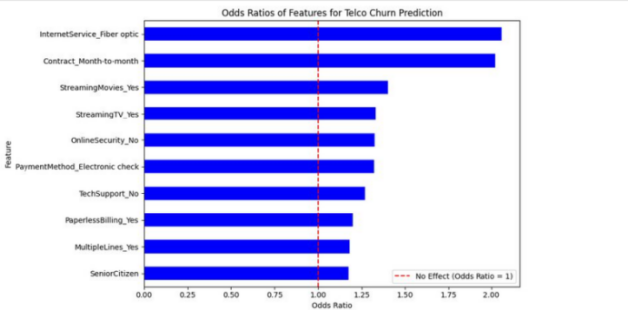
The system produces individual churn risk probabilities and highlights the key behavioral drivers behind potential churn, such as declining engagement or low feature adoption. This interpretability allows customer success and operations teams to take focused, cost-effective retention actions rather than broad, reactive interventions.
Modeled in a SaaS context with a 5% monthly churn rate and $50 ARPU, the prototype demonstrates how even small improvements in retention can translate into meaningful protection of recurring revenue. Built as an extensible analytics solution, it can support automation, monitoring, and integration into existing customer management workflows.
Audience: Customer success teams, business analysts, telecom operators, and subscription-based businesses.
Telco Churn Drivers: Odds Ratio Feature Importance
Technologies:
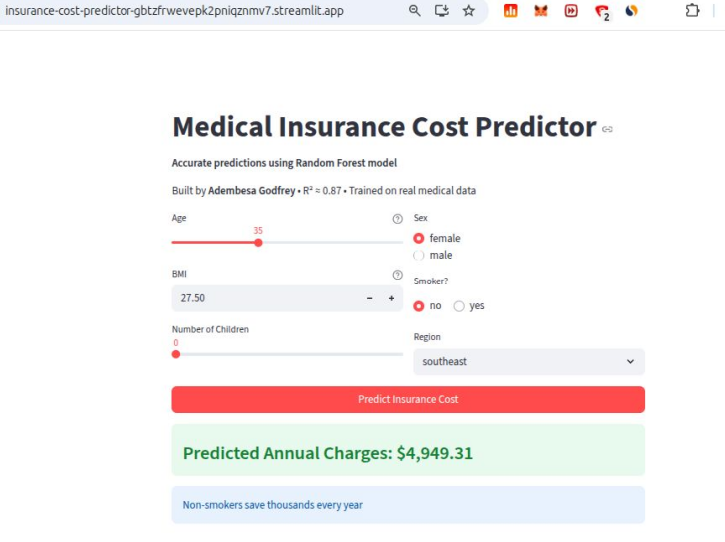
Insurance Risk Evaluation & Decision Support App – Data-Driven Pricing Insights
Accurately assessing insurance premiums is essential to balance profitability and customer fairness. This prototype predicts individual insurance costs based on factors such as age, lifestyle, smoking habits, and dependents, helping insurers make informed pricing decisions quickly and reliably.
By highlighting the key drivers of risk for each customer, the tool supports interpretable, actionable decisions, allowing insurers to optimize pricing, reduce exposure to high-risk policies, and enhance customer satisfaction. Built as an interactive Streamlit application, it can be extended for cloud deployment, multi-user access, automated data ingestion, and ongoing performance monitoring.
Audience: Insurance analysts, underwriters, actuaries, and financial planning teams.
Insurance Cost Prediction App – User Interface
Technologies: